Teaching models to think, for cheap!
Thoughts, takeaways, and muses on the s1 model paper... and where we can go.
TLDR
- s1 is a supervised fine-tuned Qwen2.5-32B-Instruct
- s1 took 16 minutes to tune on
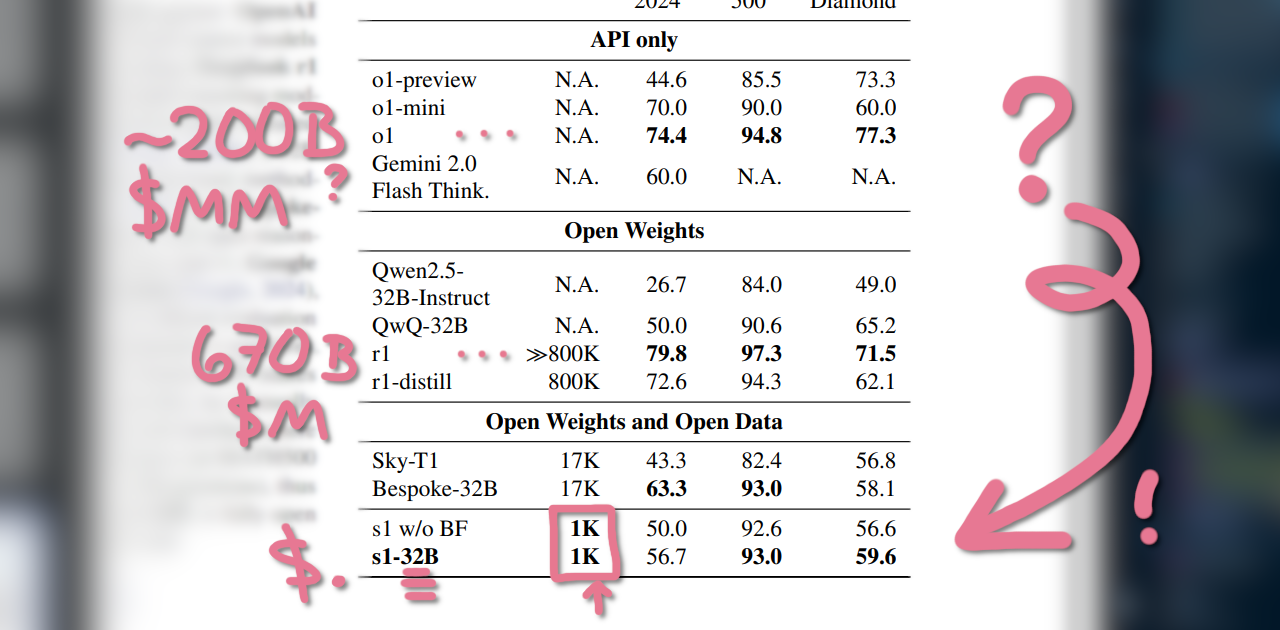
16x H100GPUs $=$ ~$6 - s1 comes very close to OpenAI’s o1 + DeepSeek’s R1 on MATH500, GPQA Diamond, and AIME24 eval datasets for its size
- Test-time budget forcing: increase or truncate the time the model spends thinking by using
Waitor</think>$=$ very effective - Qwen2.5-distilled dataset of 1,000 tokens, refined from 56k by Quality, Difficulty, and Diversity
- 1k tokens was more than enough to max accuracy – 56k did not perform better!
> kanomeister :enter
I came across a great article by Tim Kellogg1 covering s1, a supervised fine-tuned version of Qwen2.5-32B-Instruct trained on a very small refined (1k!) dataset, with some clever tricks to limit time and budget with a Wait token that forces a model to second-guess itself. (original paper here)2
My takeaways:
Controlling the time the model has to think by forcing tokens is an effective budgeting tool – and a great second-guess enabler!
You don’t need a lot to make a model think. 16 minutes of 16x H100s for training $=$ ~$6, for a large model that can effectively run on a PC at home.
More data doesn’t necessarily mean better thinking! 1k was a plateau for their accuracy marks; 59k didn’t improve the model.
From the nerd perspective, what I like is that this demonstrates how we’re able to have the model intelligently resample its learned “function”, manifested as a form of self-checking, to get a better probability of being “correct”.
It does what we do day-to-day, which is go “wait!” LOL
And the complexity reduction aligns with what I was thinking after reading R1: we could do it with less, right? It also means that I anticipate a boost in more specialized datasets, especially with longer domain-focused reasoning chains. If we combine these intermediate stops with triggers to query some external tool or run a quick Python script and expect a result, I can imagine some pretty wild autonomous improvements on top of this.
I think we can also bridge this to MoE, where each expert can learn separate domains and then integrate them together to form novel reasoning. We don’t do this yet, but I think the wires are right there to be crossed, if we allow some kind of latent context activation to occur (hopefully in a way that doesn’t over-complicate the already-strenuous load of parallizing the models).
I want to see it go “This reminds me of X and Y, so let’s try Z in a similar vein.” – that would represent a significant leap forward!
I think it means being extremely picky with the dataset. Perhaps there is a self-supervised refinement process that can fill for or augment SFT, given target metrics? Might use up more training time, but I think for smaller models it’s great for squeezing the most out of them – and we’ve seen with S1 what is possible there.
I also think this will begin to put emphasis on reasoning distillation, where smaller models will be able to match or even outclass their larger companions, to a point – which makes me think of how close it is to inheritance.
Distilling is a bit genetic, don’t you think?
One of the prime ways we as silly humans learn is by mimicking others, after all… though a gap I think we’re missing is that “learn by trial and error” reinforcement method. Gotta get a model to think about why it was wrong during training, maybe… whether it can validate that itself or it needs to be taught that by a data source or a tool.
Which is why I also still think there are improvements we can make on incorporating that into the head without losing the transparency of thought or inference-time efficiency. Time to test a few ideas on an even smaller model…
Strongly appreciate the commitment to open research here, by the way. We don’t have enough of it, and the last thing we need are Cyberpunk-style mega-corporations and hedge funds leveraging these for nothing but shareholder gain… we know how that ends.
What does s1 have us thinking, gang?